| 1-G-3-5 | 戞侾俈夞堛椕忣曬妛楢崌戝夛丂17th JCMI(NOV,.1997) |
仜壀杮 桾巌 , 徏懞 懽巙 , 壀揷 晲晇 , 孠揷
惉婯 , 拞懞 峫巙 , 拞栰 桾旻 , 晲揷 桾
戝嶃戝妛堛妛晹晅懏昦堾堛椕忣曬晹
A model of acquirement of knowledge from the
clinical database system
the case of clinical laboratory test data
仜Yuji Okamoto , Yasushi Matsumura , Takeo
Okada , Shigeki Kuwata , Takasi Nakamura , Hirohiko
Nakano , Hiroshi Takeda
Department of medical Information Science, Osaka University Hospital(okamoto@hp-info.med.osaka-u.ac.jp )
Keywords丗 database system, hospital information system, acquirement of knowledge
昦堾忣曬僔僗僥儉偺壱摥偵傛傝丄懡偔偺僨乕僞偑僨乕僞儀乕僗偵拁愊偝傟傞傛偆偵側偭偨丅崱屻丄恌椕僨乕僞偺揹巕壔偼丄峏偵峀偑傞孹岦偵偁傞丅偙偺拁愊偝傟偨戝検偺僨乕僞偐傜恌椕偵桳梡側忣曬傪拪弌偡傞偙偲偼廳梫側壽戣偱偁傞丅崱夞変乆偼丄偁傞摿幙傪帩偮姵幰孮乮椺偊偽丄偁傞幘姵傪帩偮姵幰乯偵偮偄偰丄斾妑揑摼傗偡偄暋悢偺姵幰僨乕僞偺拞偵昞傟傞摿挜傪拪弌偡傞曽朄偵偮偄偰専摙偟偨丅廬棃丄偙偆偟偨栤戣偵偼丄敾暿暘愅朄偑梡偄傜傟偰偒偨偑丄偙偺曽朄偱偼丄僨乕僞嬻娫傪暯柺偱俀暘偡傞偙偲偵側傝丄摿挜拪弌偺曽朄偲偟偰偼丄傗傗rough偲側傞壜擻惈偑偁傞丅変乆偼丄偁傞摿幙傪桳偡傞姵幰孮偑丄僨乕僞嬻娫偵偍偄偰斾妑揑彫偝側椞堟偵摿堎揑廤拞偡傞応崌偵傕丄偙傟傪尒摝偝偢丄偦偺摿挜傪拪弌偡傞曽朄偵偮偄偰奐敪傪帋傒偰偄傞丅
変乆偼丄杮堾偺姵幰僨乕僞傪丄夝愅傪愱梡偲偡傞僨乕僞儀乕僗僔僗僥儉乮恌椕僨乕僞儀乕僗1)乯偵拁愊偟偰偒偨丅僨乕僞拪弌傪帺摦壔偡傞偨傔偵丄偙偺僨乕僞儀乕僗偐傜暘愅偵梡偄傞僨乕僞傪専嶕偟丄寛傔傜傟偨宍幃偺僨乕僞僼傽僀儖偵惍偊傞僔僗僥儉傪崌傢偣偰奐敪偟偨丅偙偺儌僕儏乕儖偲暘愅偺儌僕儏乕儖傪慻傒崌傢偣傞偙偲偵傛傝丄忣曬乮抦幆乯偺拪弌偑帺摦壔偝傟傞丅
偙偺僔僗僥儉傪梡偄丄椺戣偲偟偰丄揝寚朢偺姵幰偵偮偄偰丄枛徑寣塼憸偺僨乕僞偺拞偱偺摿挜拪弌傪峴偭偨丅
恌椕僨乕僞儀乕僗偼丄儚乕僋僗僥乕僔儑儞忋乮NEC丄EWS4800乯偵丄ORACLE7傪僨乕僞儀乕僗儅僱乕僕儊儞僩僔僗僥儉偵梡偄偰峔抸偝傟偰偄傞丅丄僋儔僀傾儞僩偼丄PC9821Xa13乮NEC乯傪梡偄丄Windows95傪OS偲偟偰嵦梡偟偨丅僨乕僞儀乕僗偺栤偄崌傢偣偵偼KeySQL傪梡偄丄DDE捠怣偱儅僋儘傪憲怣偡傞偙偲偱昁梫側僨乕僞傪僒乕僶偐傜妉摼偟偨丅僾儘僌儔儉偺奐敪偵偼VisualBasic
5.0傪梡偄偨丅
専懱専嵏寢壥偺僨乕僞偼丄僨乕僞奿擺岠棪傪忋偘傞偨傔偵丄埲壓偺僨乕僞儀乕僗僼傽僀儖偵奿擺偝傟偰偄傞丅懄偪丄枛徑寣塼丄擜専嵏丄昿搙偺懡偄惗壔妛専嵏側偳偺僙僢僩偱寢壥偑弌偝傟傞専嵏崁栚偺僨乕僞偵偮偄偰偼丄僙僢僩枅偵嶌惉偝傟偨僼傽僀儖乮偦傟偧傟偺崁栚偑僼傿乕儖僪偵妱傝摉偰傜傟偰偄傞乯偵奿擺偝傟丄偦傟埲奜偺崁栚偺僨乕僞偼丄僨乕僞崁栚柤偺僼傿乕儖僪傪帩偮侾偮偺僼傽僀儖偵奿擺偝傟偰偄傞丅僨乕僞拪弌儌僕儏乕儖偼丄僨乕僞儀乕僗僼傽僀儖偐傜娭怱偺偁傞崁栚偺僨乕僞傪拪弌偟丄僋儔僀傾儞僩懁偱摨堦姵幰丄摨堦擔偺僨乕僞偑侾儗僐乕僪偲側傞傛偆偵曇廤偡傞丅偙偙偱丄堦恖偺姵幰偵偮偄偰暋悢偺儗僐乕僪偑懚嵼偡傞応崌偼丄嵟弶偵峴傢傟偨専嵏偺傒傪巆偟偨丅
崱夞偼丄姵幰偺摿幙傪婯掕偡傞僨乕僞偲偟偰丄専懱専嵏僨乕僞傪梡偄偨丅姵幰偺摿幙傪婯掕偡傞僨乕僞傪栚揑曄悢丄偦偺摿挜拪弌偺懳徾偲側傞僨乕僞崁栚傪愢柧曄悢偲屇傇偙偲偵偡傞丅N屄偺愢柧曄悢偵懳偟丄傑偢偦傟偧傟偺抣偑懚嵼偡傞斖埻傪摍娫妘偺嬫堟偵暘妱偡傞丅偙偺N屄偺奺梫慺偺嬫堟偵埻傑傟偨N師嬻娫傪僙儖偲屇傇偙偲偵偡傞丅奺僙儖偵偮偄偰丄僙儖撪偵娷傑傟傞梫慺偺悢偲丄偙偺拞偱偁傞摿幙傪桳偡傞梫慺偺斾棪Rc偐傜丄曣廤抍偵偍偗傞斾棪偺99亾怣棅嬫娫乮忋尷抣丗Uc丄壓尷抣丗Lc乯傪媮傔偨丅慡懱偺梫慺偺悢偵懳偡傞摿幙傪桳偡傞梫慺偺斾Rt偲丄奺僙儖偺Rc丄Lc丄Uc偺抣傪斾妑偟偰丄奺僙儖傪暘椶偟偨丅懄偪丄Rt
嵟弶偵梌偊偨愢柧曄悢偺撪丄慡偰偺曄悢偑偙偺摿幙傪昞偡偺偵桳岠側堄枴傪傕偮偲偼尷傜側偄丅偦偙偱丄嵟弶偵巊梡偟偨N屄偺愢柧曄悢偐傜堦偮傪彍偄偰忋婰偺張棟傪峴偄丄Lcls,max傪媮傔偨丅偙偆偟偰媮傔傜傟偨N屄偺抣偺撪丄嵟傕戝偒側抣傪偲偭偨傕偺偑曄悢傪尭傜偡慜偺抣偵懳偟偰10亾埲忋掅壓偟側偄応崌偵丄偙偙偱彍偐傟偨曄悢偼堄枴偺柍偄曄悢偲傒側偟偨丅偙偺僾儘僙僗傪孞傝曉偟丄嵟廔揑偵巆偭偨愢柧曄悢偑丄偙偺摿幙傪傕偮梫慺偺摿挜傪昞偡僨乕僞崁栚丄傑偨偙偙偱媮傔傜傟偨僋儔僗僞乕傪偦偺梫慺偑摿堎揑偵廤傑傝傗偡偄椞堟丄懄偪摿挜傪昞偡椞堟偲偟偰嵦梡偟偨丅
椺戣偲偟偰丄枛徑寣塼偺僨乕僞偵偍偗傞揝寚朢偺姵幰偺摿挜傪丄杮朄傪梡偄偰拪弌偟偨丅僨乕僞拪弌儌僕儏乕儖偵傛傝WBC丄RBC丄Hb丄Ht丄Plt媦傃Fe偺専嵏偵偮偄偰摨堦擔偵巤峴偝傟偨専嵏僨乕僞乮姵幰偺廳暋傪彍偔乯傪1997擭4寧偐傜6寧傑偱偺婜娫専嶕偟丄張棟偺偨傔偺僨乕僞僼傽僀儖傪嶌惉偟偨丅偦偺儗僐乕僪悢偼1081偱偁偭偨丅偙偙偱丄Fe偑惓忢壓尷抣枹枮偺傕偺傪揝寚朢偺姵幰偲偟偨丅杮朄偺張棟偵傛傝摼傜傟偨Lcls,max偼丄5偮偺曄悢偺帪0.708偱偁偭偨丄師偵曄悢傪堦偮彍偄偰摼傜傟偨Lcls,max偼丄
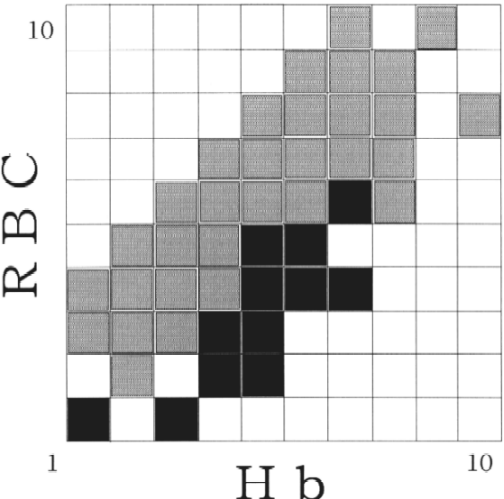
Plt傪彍偄偨帪偵嵟戝抣傪偲傝丄偦偺抣偼0.733偱偁偭偨丅偙偺抣偼愭偺抣偵懳偟偰10亾埲忋偺掅壓偑側偄偺偱Plt偼桳岠側愢柧曄悢偐傜彍偐傟偨丅摨條偵偝傜偵侾偮偺曄悢傪彍偄偨偲偒偵Lcls,max偑嵟戝抣傪偲傞偺偼WBC傪彍偄偨帪偱偁偭偨丅偦偺抣偼0.766偲側傝丄愭偺抣偵懳偟偰10亾埲忋偵掅壓偑柍偄偺偱WBC偼桳岠側曄悢偐傜彍偐傟偨丅師偺僗僥僢僾偱偼丄Hb傪彍偄偨帪Lcls,max偑嵟戝抣偲側傞偑丄抣偼0.630偲側傝丄10亾埲忋掅壓偡傞偨傔丄Hb偼桳岠側曄悢偐傜彍偐側偐偭偨丅寢嬊5偮偺曄悢偺撪丄偙偺僾儘僙僗偱彍偐傟偨偺偼Plt偲WBC偱偁傝丄巆傝偺Ht丄RBC丄Hb偑揝寚朢姵幰偺摿挜傪昞偡曄悢偲偟偰巆偭偨丅嵟廔揑偵媮傔傜傟偨僋儔僗僞乕偺丄RBC偲Hb偺暯柺傊偺搳塭傪恾侾偵帵偡丅Ht丄RBC丄Hb偺曄悢偱峔惉偝傟傞1000屄偺僙儖偺撪丄僨乕僞偑懚嵼偡傞偺偼79屄偺僙儖偱偁偭偨丅傑偨丄偙偺撪揝寚朢姵幰偺摿挜傪昞偡僋儔僗僞乕傪峔惉偡傞偺偼16屄偺僙儖偱丄偙偺拞偵142屄偺梫慺偑娷傑傟偰偄偨丅偙偺僋儔僗僞乕撪偺梫慺偺偆偪丄揝寚朢姵幰偺梫慺偼119屄乮83.8亾乯偱偁偭偨丅偙傟偼丄慡懱偺梫慺乮1081乯偺撪丄揝寚朢偺姵幰乮312乯偑娷傑傟傞妱崌28.9偵懳偟丄廫暘崅抣偱偁偭偨丅偙偺僋儔僗僞乕偵傛傞揝寚朢偺桳柍偺悇掕偵偮偄偰丄sensitivity偼0.38丄specificity偼0.97偱偁偭偨丅
丂恌椕僨乕僞儀乕僗偐傜丄帺摦揑偵偁傞摿幙傪帩偮姵幰偺摿挜傪昞偡僨乕僞傪拪弌偡傞僾儘僌儔儉傪奐敪偟偨丅偙偺僔僗僥儉傪梡偄丄枛徑寣塼憸偐傜丄揝寚朢姵幰偺摿挜傪拪弌偟偨偲偙傠丄廬棃偐傜尵傢傟偰偄傞彫媴惈彫怓慺惈昻寣偲堦抳偟偨丅偙偺僔僗僥儉偼丄擟堄偺摿幙傪帩偮姵幰偵偮偄偰専懱専嵏僨乕僞偱偺摿挜拪弌傪壜擻偲偡傞丅崱屻丄峏偵丄杮朄偺懨摉惈丄揔墳斖埻偺晛曊惈偵偮偄偰専摙偡傞昁梫偑偁傞丅傑偨丄枹偩敪尒偝傟偰偄側偄抦幆偑丄偙偺僔僗僥儉偵傛傝摼傞偙偲偑偱偒傞偐丄専摙偟偰偄偔梊掕偱偁傞
丂愢柧丗僋儔僗僞乕偺RBC偲Hb偺暯柺傊偺搳塭丅崟怓偼Fe寚朢姵幰偺梫慺偑摿堎揑偵廤傑傞椞堟丄奃怓偼姵幰偺梫慺偑懚嵼偡傞椞堟
侾丏孠揷惉婯 懠丗恌椕巟墖僨乕僞儀乕僗偺峔抸媦傃偦偺棙梡丏戞15夞堛椕忣曬妛楢崌戝夛榑暥廤, 929, 1995
{kind=link}